OPT-16 Optimize arithmetic by unboxing float, int and bool values#
Background#
CPython’s value stack can only contain PyObject* (Python objects). So the result of operations must always be an object. This makes complete sense for Python’s
garbage collection and reference counting, but it has a downside in that lots of short-lived objects are created to only pass values between opcodes.
For example,
x += y * z
The result of y * z is an object that must be allocated as the result the BINARY_MULTIPLY opcode. The resulting value is immediately discarded when it is added to z.
IF the resulting value fits into a 64-bit CPU register, e.g. a long long, long or double, then it would be more efficient to keep the interim value
in its native type and not initialize the Python object until it’s needed. This is called “escaping” and escape analysis is something that exists in almost all JIT compilers.
Work was done in early versions of Pyjion to box/unbox Python integers and floats into native long/float types. This allows for native CIL opcodes like ADD, SUB, IMUL, etc. to be used
on native integers instead of having to use the complex (and slow) PyLongObject/PyFloatObject operations.
I’ve found this initial prototype to be unstable so the boxing and unboxing has been completely rewritten.
Solution#
Pyjion’s escape analysis is achieved using an instruction graph to traverse supported unboxed types and opcodes then to tag transition stack variables as unboxed. This functionality complements PGC.
Pyjion uses the .NET JIT compiler’s value stack instead of CPython’s value stack. In this optimization:
floating point values are “unboxed” by loading the address of
ob_fval(the double of thePyFloatObject) onto the stack and boxed where the value needs to be escaped usingPyFloat_FromDouble().integer values are converted to
int64_tusingPyLong_AsLongLongboolean values are converted to
int32_tusing a pointer comparison withPyTrueandPyFalse
The optimization’s efficiency is from its escape analysis, which is crude compared with PyPy, but a start nonetheless.
Take this code sample:
def f():
text = [0.1,1.32,2.4,3.55,4.5]
n = 2.00
text[0] += 2. ** n
return text
The first compilation of this method doesn’t know what type text[0] is, but with PGC it will observe the type and recompile into a more efficient tree by using an unboxed ADD opcode.
Pyjion can create DOT graphs when compiled with DUMP_JIT_TRACES, the unboxing graph for this function looks like this:
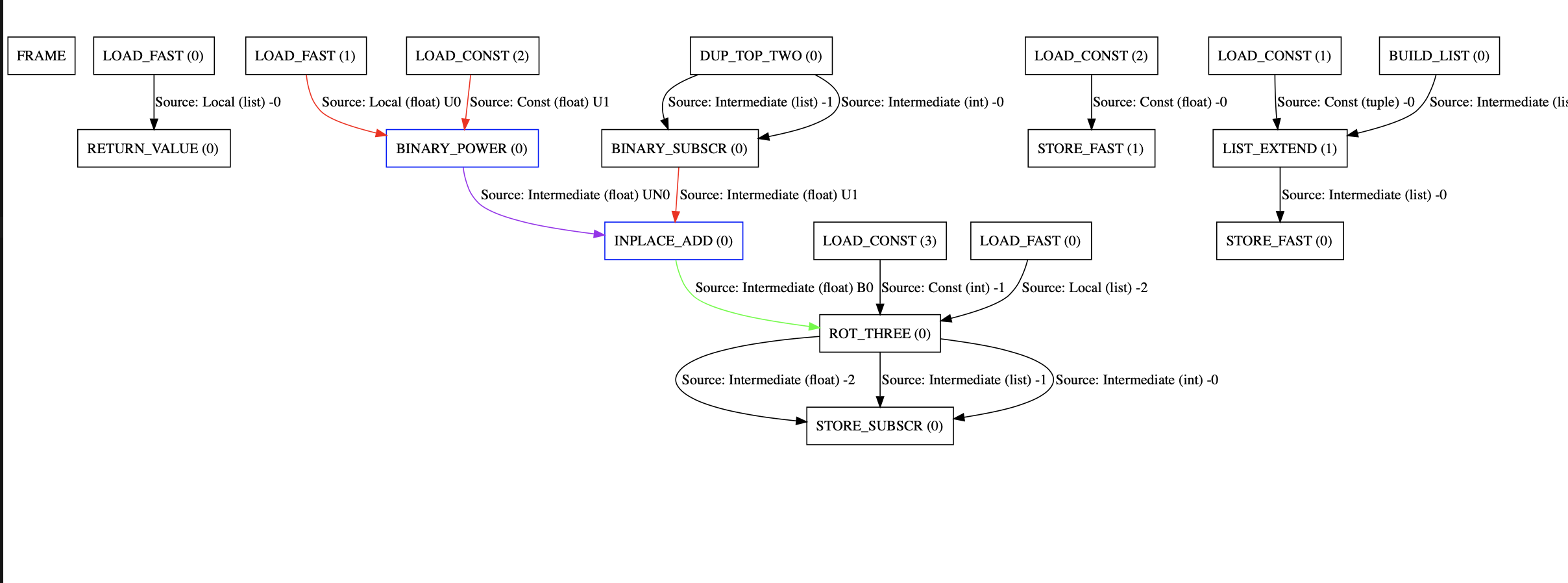
The purple edges show values which fit within a 64-bit value, and so use .NET’s register allocator to optimize them. Green edges are box operations and red edges are unboxing operations.
The n-body benchmark has an extreme version of this:
mag = dt * ((dx * dx + dy * dy + dz * dz) ** (-1.5))
The operations will form a graph of instructions, for which Pyjion will mark the edges as escaped. All of the binary operations in the escaped types can use native assembly to add and multiply floating point values. Also, the values are not kept within Python objects, so the code is faster to execute as it doesn’t create temporary objects between opcodes.
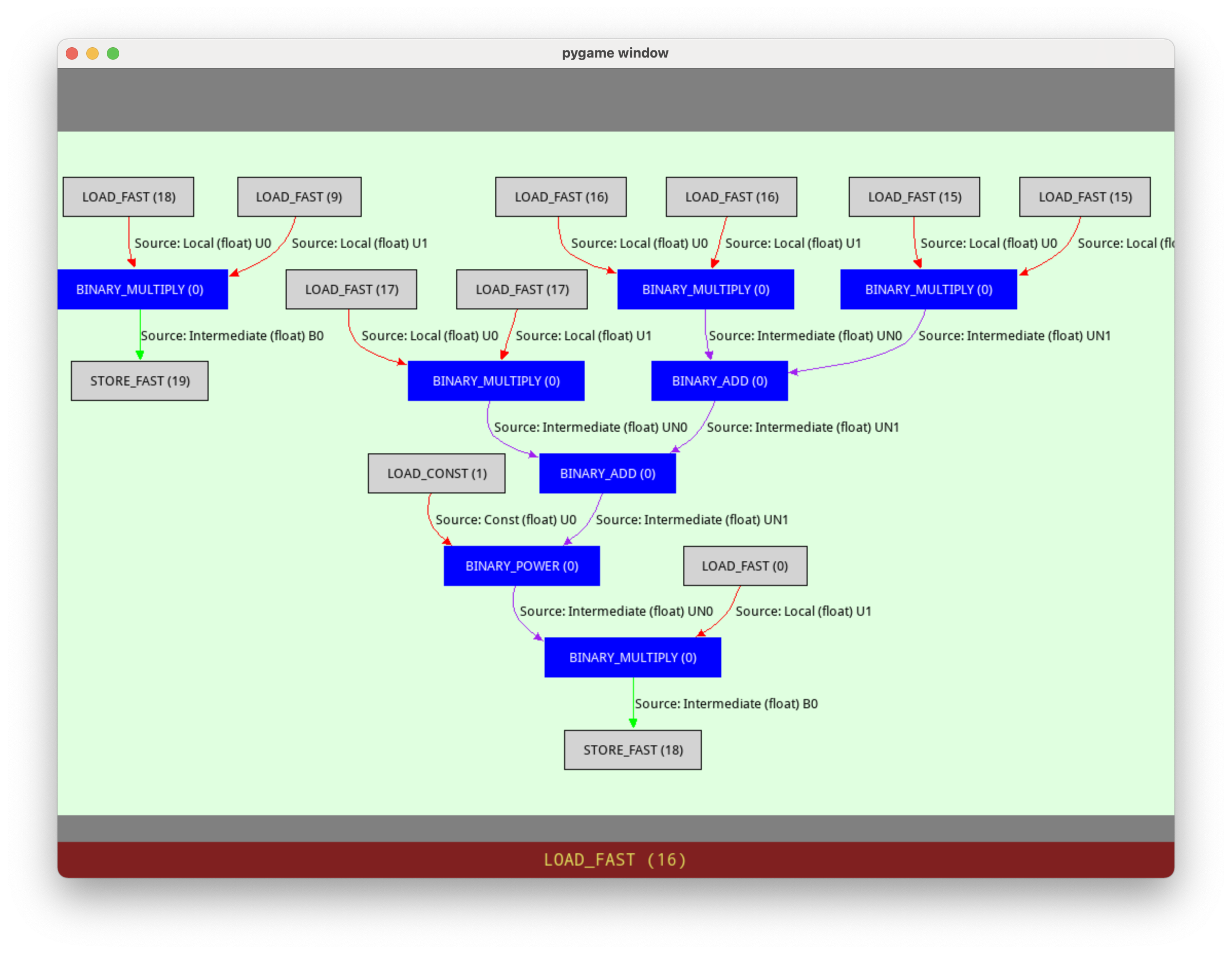
This demonstrates the principle around temporary objects.
Gains#
Floating point arithmetic is significantly faster (2-10x)
Integer arithmetic is significantly faster (2-10x)
Mixed arithmetic (float and int) is faster
Edge-cases#
Pyjion will throw a
ValueErrorsaying that the PGC guard failed when an assertion was made from type data and the type changed at runtime.Pyjion will try very hard to detect values that would overflow a
int64_t, but in some cases it could throw an Overflow error as a Python exception
Further Enhancements#
Instead of raising a runtime exception, Pyjion could compile a parallel call graph for which to execute the “generic” sequence of instructions.
Support other types (array)
Configuration#
This optimization is enabled at level 1 by default. See Optimizations for help on changing runtime optimization settings.